ConcurrentHashMap源码分析
jdk1.8ConcurrentHashMap解析
本文部分内容来源于互联网和jdk1.8源码,如有不对请谅解并指正
1、前言
ConcurrentHashMap是一种同步的map,因为HashMap在多线程情况下不安全,而HashTable锁粒度又太大,所以出来了ConcurrentHashMap。
正式开始之前,先说明一个参数,这是HashMap里面没有的。
sizeCtl
1 | /** |
用来控制table的初始化和扩容的操作,不同的值有不同的含义。
- sizeCtl=0 未初始化,并且没有指定初始容量。
- sizeCtl>0 可能未初始化,由指定的初始容量计算而来,这和HashMap初始化时指定大小是一个意思。也可能已经初始化完成,值为table.length * 0.75,是阈值大小。
- sizeCtl=-1 正在初始化。
- sizeCtl=-N 正在初始化。高15位是指定容量标记,低16位表示有m+1个线程在并行扩容。
2、put()方法
下面具体说一下put里面用到的方法。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());//hash操作
int binCount = 0;
//bitCount表示i处的节点数量,用来判断是否转换成红黑树
for (Node<K,V>[] tab = table;;) {//CAS插入
Node<K,V> f; int n, i, fh;
//除非构造时指定初始化集合,否则默认构造不初始化table
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null)))
//当前table位置没有节点,创建一个新的
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
//当前节点正在扩容,让当前线程帮助扩容,扩容完指向新的table
else {
//正常插入到链表或者红黑树当中
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {//表明是链表结点类型
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
//onlyIfAbsent表示是新元素才加入,旧值不替换,默认为fase。
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
//加入链表尾部
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {//是红黑树
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
//默认table的一个链表结点数超过8个数据结构会转为红黑树
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);//更新size,检测扩容
return null;
}2.1 initTable()
初始化table,通过volatile的sizeCtl,置为-1,保证可见性,这样同时只有一个在初始化了。如果别的线程检测到sizeCtl为-1,就会 Thread.yield() 让出CPU一会。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2);//扩容阈值为新容量的0.75倍
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}2.2 tabAt()/casTabAt()/setTabAt()
ABASE表示table中首个元素的内存偏移地址,所以(long)i << ASHIFT) + ABASE得到table[i]的内存偏移地址。这里像C语言一样,直接操作内存了。casTabAt才能保证原子性,setTabAt并不能,只有在有锁的时候,才能用setTabAt。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
// getObjectVolatile:通过给定的Java变量获取引用值。
//这里实际上是获取一个Java对象o中,获取偏移地址为offset的属性的值。
//此方法可以突破修饰符的抑制,也就是无视private、protected和default修饰符。
//会强制从主存中获取属性值。
}
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,
Node<K,V> c, Node<K,V> v) {
return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
static final <K,V> void setTabAt(Node<K,V>[] tab, int i, Node<K,V> v) {
U.putObjectVolatile(tab, ((long)i << ASHIFT) + ABASE, v);
//设置值的时候强制(JMM会保证获得锁到释放锁之间所有对象的状态更新都会在锁被释放之后)更新到主存,
//从而保证这些变更对其他线程是可见的。
}3、 扩容
首先要了解扩容的时机。 - put的末尾会调用addCount,这里面检查扩容。
- 链表转红黑树(链表长度大于8)时如果table长度小于64(MIN_TREEIFY_CAPACITY),则会触发扩容。
- putAll一次加入很多元素。
后两种情况都会调用tryPresize()。
3.1 addCount()
1 | private final void addCount(long x, int check) { |
rs即resizeStamp(n),与RESIZE_STAMP_SHIFT配合可以求出新的sizeCtl的值,分情况如下:
- sc >= 0
表示没有线程在扩容,使用CAS将sizeCtl的值改为(rs << RESIZE_STAMP_SHIFT) + 2)。 - sc < 0
已经有线程在扩容,将sizeCtl+1并调用transfer()让当前线程参与扩容。
这两个值算完就是sizeCtl。高15位是指定容量标记,低16位表示有m+1个线程在并行扩容。
3.2 tryPresize()
1 | private final void tryPresize(int size) { |
3.3transfer()
transfer是真正进行扩容的方法。
迁移过程图例:
单线程:
多线程:
源码:
1 | // tab是旧table,nextTab是新table |
扩容过程中的链表复制过程:
为什么要分成高低位链表:
ConcurrentHashMap的hash算法决定了扩容后的节点只有两个去处,i或者 i+n。
3.4. helpTransfer()
添加删除节点时,如果table[i]在扩容,就会调用helpTransfer()。
1 | final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) { |
4、get()方法
get方法可以保证取出的值一定是最新的,但是get并没有加锁,因为Node是volatile的。
1 | public V get(Object key) { |
get图解: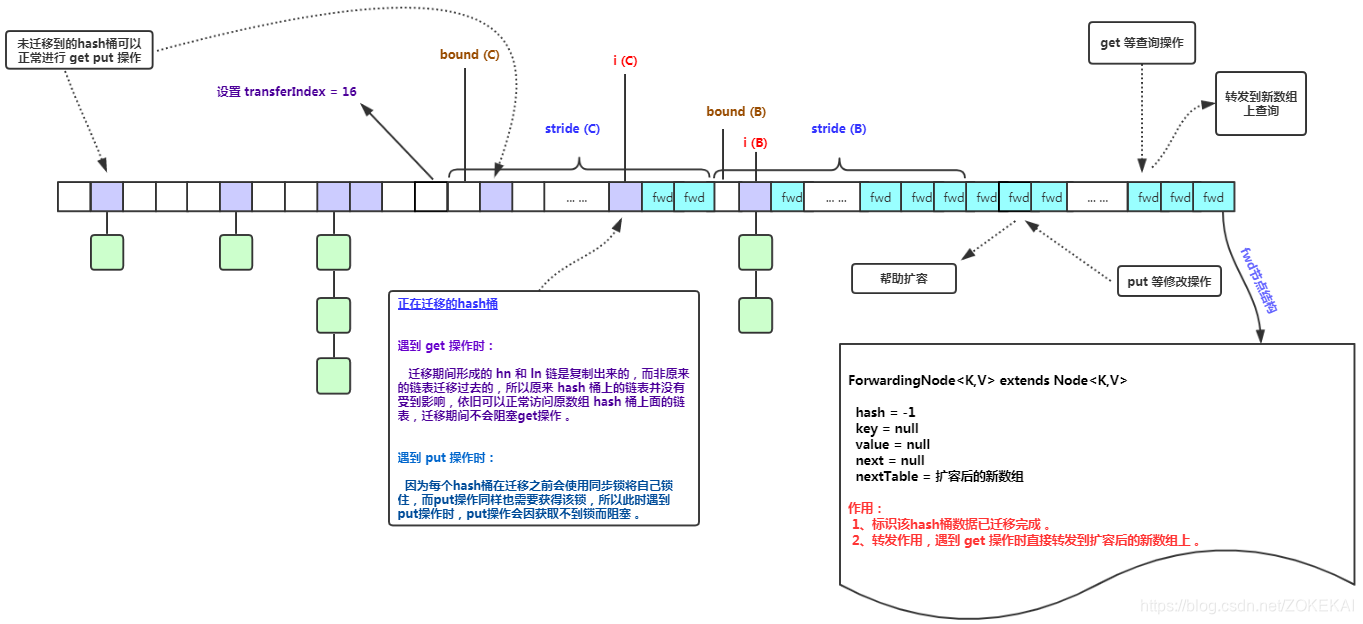
参考文章:
https://blog.csdn.net/tp7309/article/details/76532366
https://blog.csdn.net/ZOKEKAI/article/details/90051567
https://mp.weixin.qq.com/s?__biz=MzI0MzI1Mjg5Nw==&mid=2247483756&idx=1&sn=356b23cb9649579a0e4853010b6fb23e
https://segmentfault.com/a/1190000016124883